ЁЁЁЁЩшЯыетбљвЛИіГЁОАЃКФудкзЗвЛИіИеИезЊЙ§НжНЧЕФШЫЁЃЪгЯпБЛНЈжўЮяЕВзЁСЫЃЌФуПДВЛМћЫћЁЃЕЋФуЕФДѓФдВЂВЛЛсвђДЫЯнШыУЃШЛЃЌФуЬ§ЕНСЫНХВНЩљЕФЗНЯђЃЌФуМЧЕУЫћИеВХЕФЫйЖШЃЌФуЖдНжЕРЕФИёОжгажБОѕадЕФХаЖЯЁЃгкЪЧФуХаЖЯГіЫћПЩФмдкФФИіЗНЯђЃЌМгПьВНЗЅзЊЙ§ЙеНЧЁЃ
ЁЁЁЁетИіПДЫЦЦНГЃЕФЫВМфЃЌЦфЪЕЭъГЩСЫвЛДЮМЋЦфИДдгЕФ“ЖрИаЙйШкКЯЭЦРэ”ЃКЪгОѕЁЂЬ§ОѕЁЂПеМфМЧвфЃЌБЛДѓФдећКЯГЩвЛИіСЌЙсЕФааЖЏХаЖЯЁЃ
ЁЁЁЁШЛЖјЃЌ
ЛњЦїШЫвЛЕЉУцЖдРрЫЦГЁОАЃЌШДЭљЭљЯнШыЪЇСщЃЌЫќЕФУПИіДЋИаЦїИїзддЫзЊЃЌЕЋЫќВЛжЊЕРИУШчКЮАбЫќУЧећКЯЦ№РДЁЃ
ЁЁЁЁЕЅвЛИаЙйЕФОжЯо
ЁЁЁЁдйОЋСМЕФДЋИаЦїЃЌЕЅЖРЪЙгУЪБЖМгаУЄЧјЁЃ
ЁЁЁЁЪгОѕЩуЯёЭЗФмПДЧхе§ЧАЗНЃЌШДПДВЛЕНЩэКѓЃЛМЄЙтРзДяФмОЋзМВтОрЃЌШДЮоЗЈЪЖБ№ЮяЬхЕФгявх(ФЧЪЧвЛжЛУЈЃЌЛЙЪЧвЛИіжНЯфЃП)ЃЛТѓПЫЗчФмВЖзНЩљвєЃЌШДЮоЗЈХаЖЯЩљдДЕФОЋШЗПеМфЮЛжУЁЃ
ЁЁЁЁОЭШчЭЌУЩзЁвЛжЛблОІХаЖЯОрРыЃЌЛђепЮцзЁЖњЖфБцБ№ЗНЯђЃЌЕЅЖРвРРЕШЮКЮвЛжжИажЊЃЌЖМЛсдьГЩбЯжиЕФаХЯЂШБЪЇЁЃ
ЁЁЁЁЖрФЃЬЌШкКЯИажЊ(Multimodal Fusion Perception)е§ЪЧЮЊСЫНтОіетИіЮЪЬтЖјЩњЕФММЪѕЗНЯђЃКНЋРДздВЛЭЌДЋИаЦїЁЂВЛЭЌЦЕЖЮЁЂВЛЭЌЪБађЕФаХЯЂНјааећКЯгыаЭЌДІРэЃЌЭЈЙ§аХЯЂЛЅВЙЃЌЬсЩ§жЧФмЯЕЭГЖдИДдгЛЗОГЕФећЬхРэНтЁЂЭЦРэКЭОіВпФмСІЁЃ
ЁЁЁЁЕквЛРрШкКЯЃКЪБПеМИКЮШкКЯ——ИуЧхГў“ЮвдкФФРя”
ЁЁЁЁЛњЦїШЫвЊааЖЏЃЌУцСйЕФЕквЛИіЙиМќЮЪЬтЪЧПеМфЖЈЮЛЃКЛњЦїШЫдкФФРяЃПжмЮЇгаЪВУДЃПБЫДЫжЎМфЕФПеМфЙиЯЕШчКЮЃП
ЁЁЁЁНтОіетРрЮЪЬтЕФЃЌЪЧМИКЮ-ПеМфзДЬЌШкКЯММЪѕЁЃЦфКЫаФФПБъЃЌЪЧНЋЖрЪгНЧЕФДЋИаЦїаХЯЂШкКЯНјЭГвЛЕФШ§ЮЌМИКЮПеМфЃЌЙЙНЈГіДјгаЪЕЪБШ§ЮЌзјБъЕФ“гявхЬхЫиЕиЭМ”ЁЃ
ЁЁЁЁBEV(ФёюЋЪгНЧ)ИажЊвдМАдкДЫЛљДЁЩЯбнНјЕФOccupancy Grid(еМгУЭјТч)ЃЌЪЧЦфжазюОпДњБэадЕФЗНАИЁЃЫќНЋРДздЖржжДЋИаЦїЃЌАќРЈЩуЯёЭЗЁЂМЄЙтРзДяЁЂКСУзВЈРзДяЕШвьЙЙЪ§ОнЃЌЭГвЛЭЖгАЕНвЛИіДгЩЯЯђЯТИЉюЋЕФзјБъЯЕжаЁЃетжжздЩЯЖјЯТЕФЪгНЧЃЌЯћГ§СЫИїИіДЋИаЦїЬигаЕФЪгНЧЛћБфгыУЄЧјЃЌЪЙЯЕЭГФмЙЛзМШЗИажЊКЭРэНтЮяЬхМфЕФПеМфЙиЯЕЃЌДѓЗљНЕЕЭЖрЪгНЧЪ§ОнШкКЯЕФИДдгЖШЁЃ
ЁЁЁЁЮоШЫМнЪЛЦћГЕЪЧетЯюММЪѕзюГЩЪьЕФгІгУГЁОАЁЃГЕСОЫФжмВМжУЕФЩуЯёЭЗКЭРзДяЃЌНЋЪ§ОнЛуШыBEVзјБъЯЕЃЌШУздЖЏМнЪЛЯЕЭГФмЙЛвЛФПСЫШЛЕи“ПДЕН”жмЮЇГЕСОЁЂааШЫКЭеЯАЮяЕФОЋШЗЮЛжУЃЌЖјВЛЪЧЫщЦЌЛЏЕиЦДДеРДздВЛЭЌЗНЯђЕФДЋИаЦїЪ§ОнЁЃ
ЖрФЃЬЌШкКЯЕФ“ШЋОАЪгНЧ”
ЁЁЁЁЕкЖўРрШкКЯЃКгявх-ЪгОѕБэеїШкКЯ——ИуЧхГў“етЪЧЪВУД”
ЁЁЁЁПеМфЖЈЮЛНтОіСЫ“дкФФРя”ЕФЮЪЬтЃЌЕЋЛЙдЖдЖВЛЙЛЃЌЛњЦїШЫЛЙашвЊРэНтЫќИажЊЕНЕФЖЋЮїОПОЙЪЧЪВУДЃЌвдМАЫќБГКѓвтЮЖзХЪВУДЁЃ
ЁЁЁЁетЪЧгявх-ЪгОѕБэеїШкКЯММЪѕвЊНтОіЕФЮЪЬтЁЃ
ЁЁЁЁДЋЭГЕФЭМЯёЪЖБ№ЫуЗЈЃЌЭЈГЃжЛФмзіЗжРрЃКетЪЧЦЛЙћЃЌФЧЪЧЯуНЖЁЃЕЋвЛеХецЪЕГЁОАЕФЭМЯёАќКЌЕФаХЯЂдЖВЛжЙгкДЫЃЌЮяЬхЕФзДЬЌЁЂЮЛжУЙиЯЕЁЂЖЏзїКЌвхЃЌЖМашвЊБЛРэНтЁЃ
ЁЁЁЁгявх-ЪгОѕБэеїШкКЯЃЌНЋЭМЯёЁЂЪгЦЕЕШЪгОѕаХЯЂгыЮФБОБъЧЉЁЂжЊЪЖЭМЦзЕШгявхаХЯЂзЊЛЏЮЊЭГвЛЕФЪ§бЇЬиеїЯђСППеМфЃЌЪЙМЦЫуЛњМШФм“ПДЖЎ”ЭМЯёЃЌгжФм“РэНт”ЦфБГКѓЕФТпМгыИХФюЁЃ
ЁЁЁЁЪгОѕгябдДѓФЃаЭ(VLM)ЪЧетвЛММЪѕЕФМЏжаЬхЯжЁЃЫќФмЙЛЭЌЪБДІРэЭМЯёКЭЮФБОЃЌИљОнЭМЯёЩњГЩУшЪіадЮФзжЃЌЛиД№ЙигкЭМЯёФкШнЕФЮЪЬтЃЌФЫжСИљОнЮФзжУшЪіЩњГЩЭМЯёЁЃ
ЁЁЁЁОпЬхЕНЛњЦїШЫгІгУЃКЕБЛњЦїШЫПДЕНвЛИізАТњШШЫЎЕФВЃСЇБЪБЃЌVLMВЛНіФмЪЖБ№Гі“ВЃСЇБ”ЃЌЛЙФмРэНт“БзгЗХдкзРзгЩЯ”“РяУцгавКЬхЁЂШнвзДђЗЁЂашвЊЧсФУЧсЗХ”“УАзХШШЦјПЩФмБШНЯЬЬ”ЁЃетжжгявхВуУцЕФРэНтЃЌЪЧЛњЦїШЫФмЙЛАВШЋЁЂЕУЬхЕижДааВйзїЕФЧАЬсЁЃ
ЁЁЁЁЕкШ§РрШкКЯЃКжїЖЏНЛЛЅЪНИажЊ——жїЖЏГіЛїЃЌдЄХаЮДРД
ЁЁЁЁЧАСНРрШкКЯЃЌЖрЩйДјга“БЛЖЏНгЪе”ЕФаджЪ——ЕШД§аХЯЂЪфШыЃЌШЛКѓДІРэЁЃЕЋШЫРрдкецЪЕЪРНчжаЕФИажЊЃЌЭљЭљЪЧжїЖЏЕФЃКЮвУЧЛсжїЖЏзЊЭЗбАевЩљвєРДдДЃЌЛсжїЖЏППНќПДВЛЧхЕФЖЋЮїЃЌЛсИљОнвбжЊЧщПідЄХаНгЯТРДПЩФмЗЂЩњЪВУДЁЃ
ЁЁЁЁжїЖЏНЛЛЅЪНИажЊШкКЯЃЌе§ЪЧИГгшЛњЦїШЫетжж“жїЖЏИажЊЁЂЖЏЬЌдЄХа”ФмСІЕФММЪѕЁЃЫќвЊНтОіЕФКЫаФЮЪЬтЪЧЃКШчКЮИќжїЖЏЁЂИќИпаЇЕиЛёШЁЖЏЬЌЛЗОГжаЕФаХЯЂЁЃ
жїЖЏНЛЛЅЪНИажЊ
ЁЁЁЁетРрЯЕЭГвЊЧѓжЧФмЬхОпБИжїЖЏЪгОѕИажЊгыЭЦРэФмСІЃКФмЙЛРэНтГЁОАжаЕФШ§ЮЌЮяРэЙиЯЕЃЌдЄВтИДдгШЮЮёЕФжДааТЗОЖЃЌЩѕжСдкжїЖЏЬНЫїжаИќаТЖдЛЗОГЕФШЯжЊЁЃ
ЁЁЁЁвЛИіЕфаЭгІгУЃЌЪЧЛњЦїШЫЕФзджїФПБъЫбЫїЃКЛњЦїШЫашвЊдкЮДжЊЛЗОГжаевЕНФГИіЮяЬхЃЌВЛЪЧТўЮоФПЕФЕиТвзЊЃЌЖјЪЧЛљгкЪЕЪБЛЗОГЗДРЁЖЏЬЌЕїећЫбЫїВпТд——ПДЕНСЫЪщзРЃЌХаЖЯЪщПЩФмдкетИННќЃЛУЛевЕНЃЌзЊЖјЫбЫїЯТвЛИіИпИХТЪЧјгђЁЃетжж“ИажЊ-дЄХа-ааЖЏ-дйИажЊ”ЕФЖЏЬЌЪЕЪББеЛЗЃЌЪЧжїЖЏИажЊШкКЯЕФКЫаФЛњжЦЁЃ
ЁЁЁЁШ§РрШкКЯЃЌжЏОЭжЧФмЕФИажЊЭј
ЁЁЁЁетШ§РрЖрФЃЬЌШкКЯИажЊММЪѕЃЌЗжБ№ЖдгІСЫВЛЭЌВуДЮЕФШЯжЊашЧѓЃК
ЁЁЁЁМИКЮЃПеМфШкКЯЃЈЮяРэВуЃЉЃКЮвдкФФЃЌжмЮЇгаЪВУДЃЌБЫДЫЕФПеМфЙиЯЕШчКЮЃП
ЁЁЁЁгявхЃЪгОѕШкКЯЃЈШЯжЊВуЃЉЃКетЪЧЪВУДЃЌвтЮЖзХЪВУДЃЌИУШчКЮДІРэЃП
ЁЁЁЁжїЖЏНЛЛЅШкКЯЃЈааЮЊВуЃЉЃКЯТвЛВНИУПДЯђФФРяЃЌдЄХаЪВУДЃЌжїЖЏзіЪВУДЃП
ЁЁЁЁОЭЯёзЗЙеНЧЕФФЧИіШЫЃКФугУЖњЖф(Ь§Оѕ)ХаЖЯЩљвєЗНЮЛ(ПеМфШкКЯ)ЃЌгУГЃЪЖЗжЮіФЧИіШЫЛЙдкБМХмЃЌВЛПЩФмЦОПеЯћЪЇ(гявхШкКЯ)ЃЌгУОбщдЄХаЫћЯТвЛВНПЩФмЭљФФИіЗНЯђХм(жїЖЏдЄХа)ЁЃетШ§епШБвЛВЛПЩЃЌЙВЭЌЙЙГЩСЫШЫРрЫВМфЭъГЩЕФзлКЯИажЊЭЦРэЁЃ
ЁЁЁЁОпЩэжЧФмЛњЦїШЫе§дкЯАЕУЭЌбљЕФФмСІЁЃетЬѕТЗЩаЮДзпЭъЃЌЕЋЗНЯђвбШЛЧхЮњЁЃ
ЁЁЁЁЃЈБОЮФЯЕеуНДѓбЇНЬЪкЁЂВЉЪПЩњЕМЪІЁЂеуНДѓбЇОпЩэжЧФмИажЊгыПижЦЪЕбщЪв(ZEAL Lab)ИКд№ШЫЁЂжаЙњвЧЦївЧБэбЇЛсПЦЦезЈМвЁЂеуНЪЁвЧЦївЧБэбЇЛсМрЪТГЄКюЕЯВЈдк“жЧИаЪРНч·вЧДДЮДРД”ЯЕСаПЦЦежБВЅжЎДгИажЊЕНПижЦЃКЖСЖЎОпЩэжЧФмаТПЦММЕФжїЬтЗжЯэЃЌЙтУїЭјМЧепаЄДКЗМећРэЃЉ
 жЧФмжЦдьЭјAPP
жЧФмжЦдьЭјAPP
 жЧФмжЦдьЭјЪжЛњеО
жЧФмжЦдьЭјЪжЛњеО
 жЧФмжЦдьЭјаЁГЬађ
жЧФмжЦдьЭјаЁГЬађ
 жЧФмжЦдьЭјЙйЮЂ
жЧФмжЦдьЭјЙйЮЂ
 жЧФмжЦдьЭјЗўЮёКХ
жЧФмжЦдьЭјЗўЮёКХ











 гЊЯњЭЦЙуVIPЛсдБДѓЩ§МЖЃЌЕШФуРДШызЄЃЁ
гЊЯњЭЦЙуVIPЛсдБДѓЩ§МЖЃЌЕШФуРДШызЄЃЁ жЧдьжБВЅжЧФмжЦдьаавЕзЈЪєжБВЅРДРВЃЌЕуЛїЩъЧы
жЧдьжБВЅжЧФмжЦдьаавЕзЈЪєжБВЅРДРВЃЌЕуЛїЩъЧы ЭјТчПЮЬУДђдьжЧдьШЫздМКЕФЭјТчПЮЬУ
ЭјТчПЮЬУДђдьжЧдьШЫздМКЕФЭјТчПЮЬУ жЧдьAPPжЧФмжЦдьAPPЃЌШУЩњвтИќШнвзЃЁ
жЧдьAPPжЧФмжЦдьAPPЃЌШУЩњвтИќШнвзЃЁ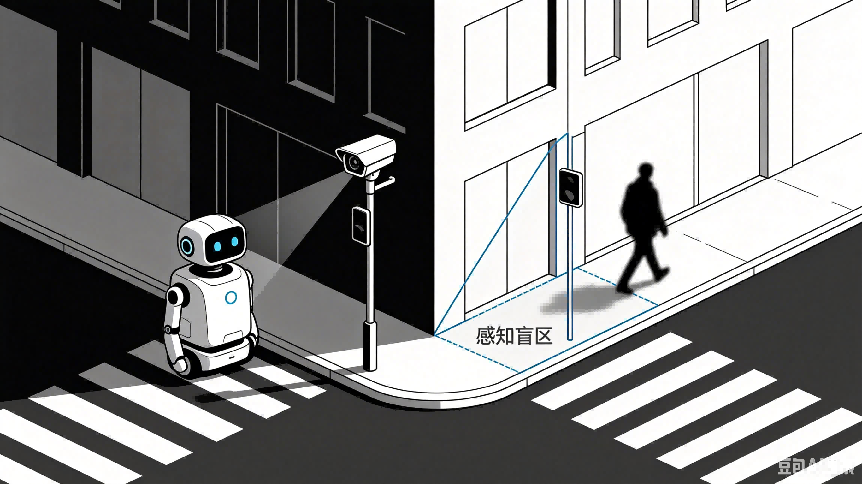




 ЭјеОПЭЗўЃК
ЭјеОПЭЗўЃК еуЙЋЭјАВБИ 33010602000006КХ
еуЙЋЭјАВБИ 33010602000006КХ

















